
注:整个理解基于以下视频,主要是记录一下视频的重点
- 【【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章】 https://www.bilibili.com/video/BV13z421U7cs/?share_source=copy_web&vd_source=2d06b9a293d399ed58c19e183f9d84da
- 【【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】】 https://www.bilibili.com/video/BV1TZ421j7Ke/?share_source=copy_web&vd_source=2d06b9a293d399ed58c19e183f9d84da
简介
Transformer是一种特殊的神经网络,一种机器学习模型,也是现在大语言模型的核心技术之一。大预言模型所做的事就是给模型输入一段话,然后让模型预测下一个词的概率,如果我们想让文本生成下去,那么就把新预测的词加入上一段对话,然后再把最新的对话再次输入Transformer,这样就可以持续进行文本生成。
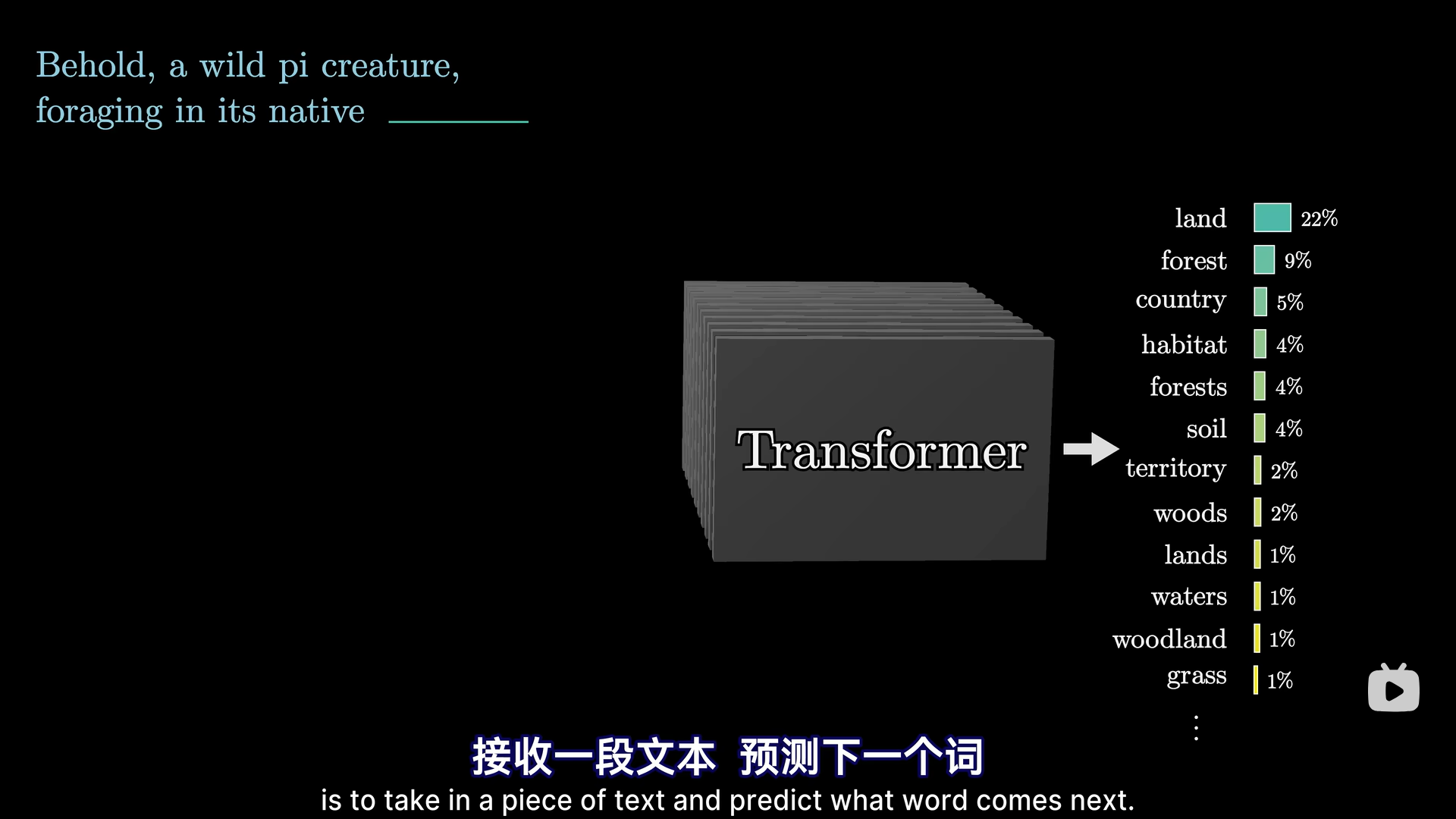 但其实Transformer能做的有很多,比如语言翻译,文本转语音,语音转文本,文本转图像等。
但其实Transformer能做的有很多,比如语言翻译,文本转语音,语音转文本,文本转图像等。
Transformer架构
输入
输入的一段话被切分成小块,称为token,在文本中,token往往是单词或者单词片段或其他常见的字符组合
 为了更好的理解,我们就先粗略的认为这些token是一个个单词。模型有一个预设的词汇库,包含所有可能得单词。
为了更好的理解,我们就先粗略的认为这些token是一个个单词。模型有一个预设的词汇库,包含所有可能得单词。
Embedding Matrix
对Embedding matrix的描述可参考下图
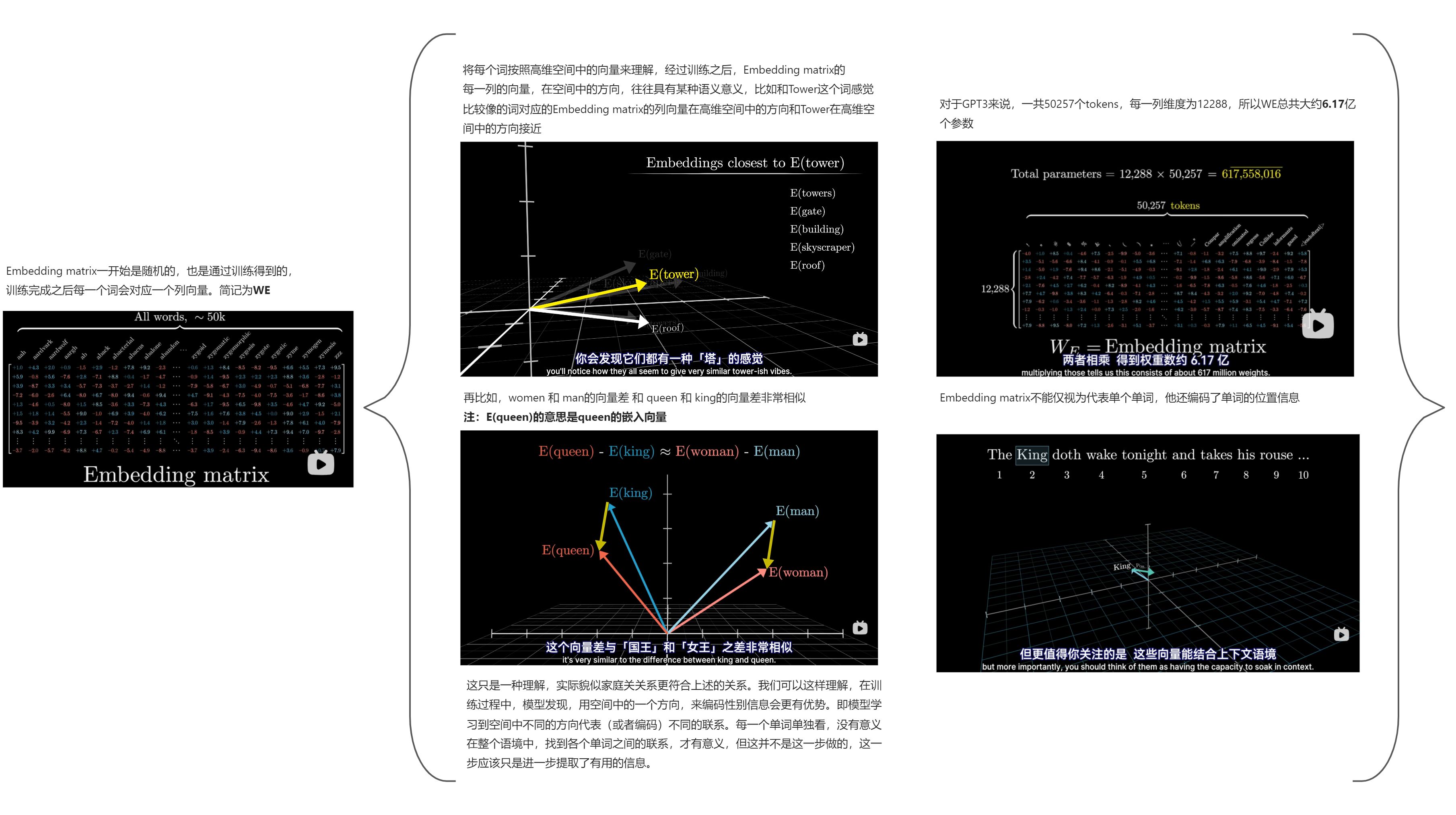
整个文本预测的简单的流程如下:例如一个代表“国王”的词向量,会被网络中的各个模块来回拉扯,最终指向一个更细致的具体的方向,也就是上下文最终将这个单词拉扯到了他应有的意义的方向上。
在第一步,即没有上下文的时候(类似于我们在chatGPT中新建对话),即根据输入文本创建向量组时,每个向量都是直接从嵌入矩阵(Embedding Matrix)中拉出来的,即最开始,每个向量只能编码单个单词的含义,没有上下文信息。而之后,流经这个网络,就能使这个词获得比单个词更丰富更具体的含义。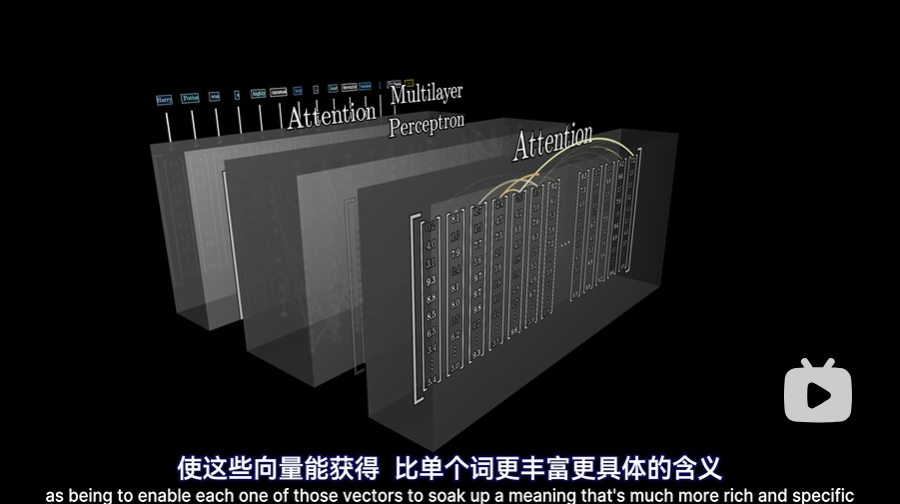
这种网络一次只能处理特定数量的向量,称作上下文长度,例如GPT-3的上下文长度为2048,因此流经网络的数据有2048列,每列12000多维度
这个上下文长度,限制了Transformer在预测下一个单词时能结合的文本量。这也是问啥早期的GPT版本在进行长对话时有时总感觉它会忘记一些东西。
输出
经过整个网络之后,输出是下一个可能token的概率分布
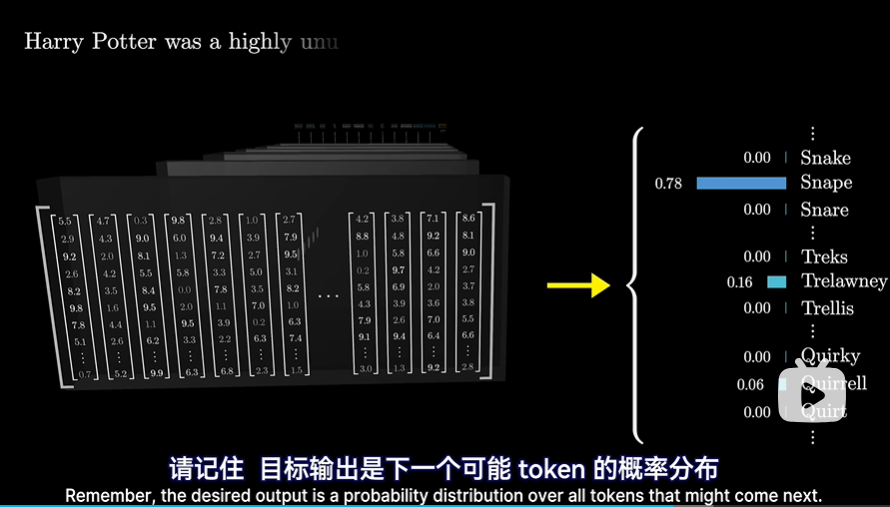
这涉及到两个步骤:
- 将上下文中的最后一个向量,通过一个矩阵(称之为“解嵌入矩阵Unembeding matrix”,记为Wu)映射到一个包含50000个值的列表中(对于chatGPT来说是50257),每个值对应词库里的一个token:
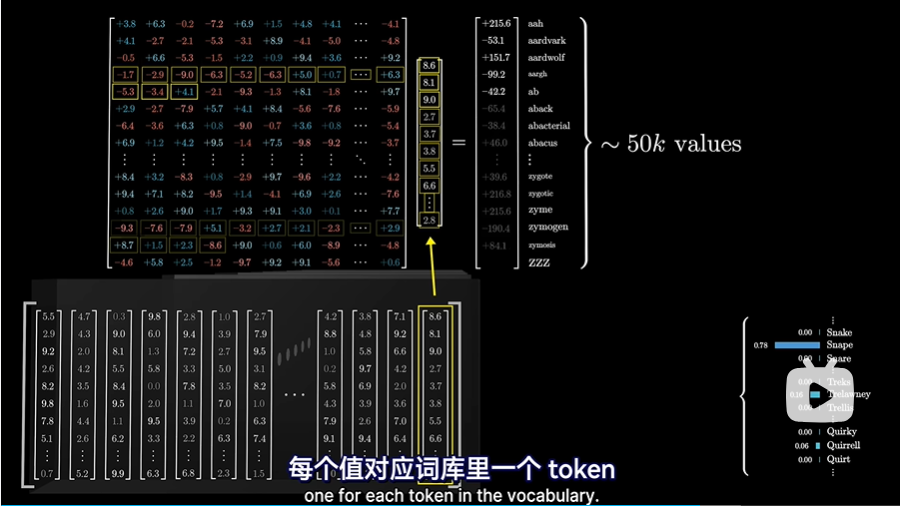
- 对那50257个值使用softmax将其归一化为概率分布:
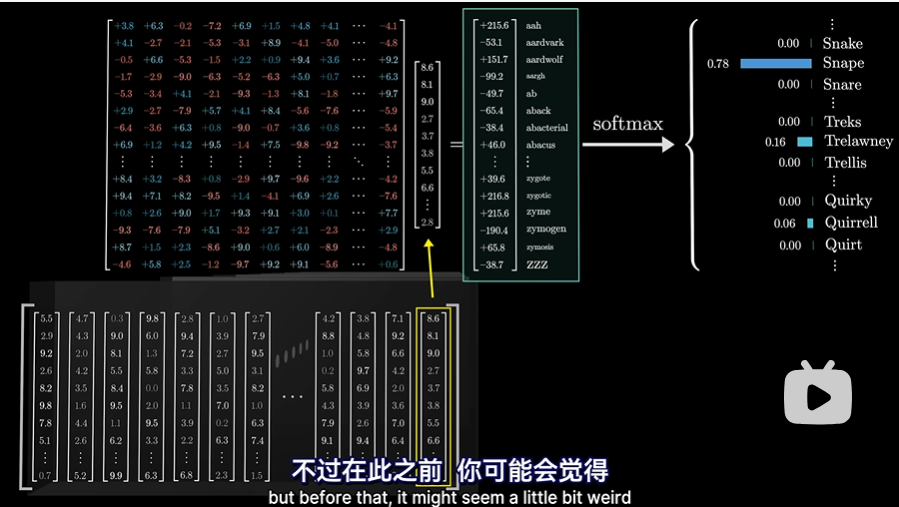
此时让我们想一下,只用最后一个嵌入来做预测,是不是有些奇怪?毕竟在最后一层中,还有成千上万的其他向量,都蕴含着丰富的上下文信息,他们中的任何一个都可以用来预测下一个token的概率,因为他们中的任何一个也已经结合了上下文信息。如果都用最后一个来做预测,那么直接使模型的最后的输出为一个列向量就好了,为啥还要有这么多输出,但我们只选取最后一列?解释如下:
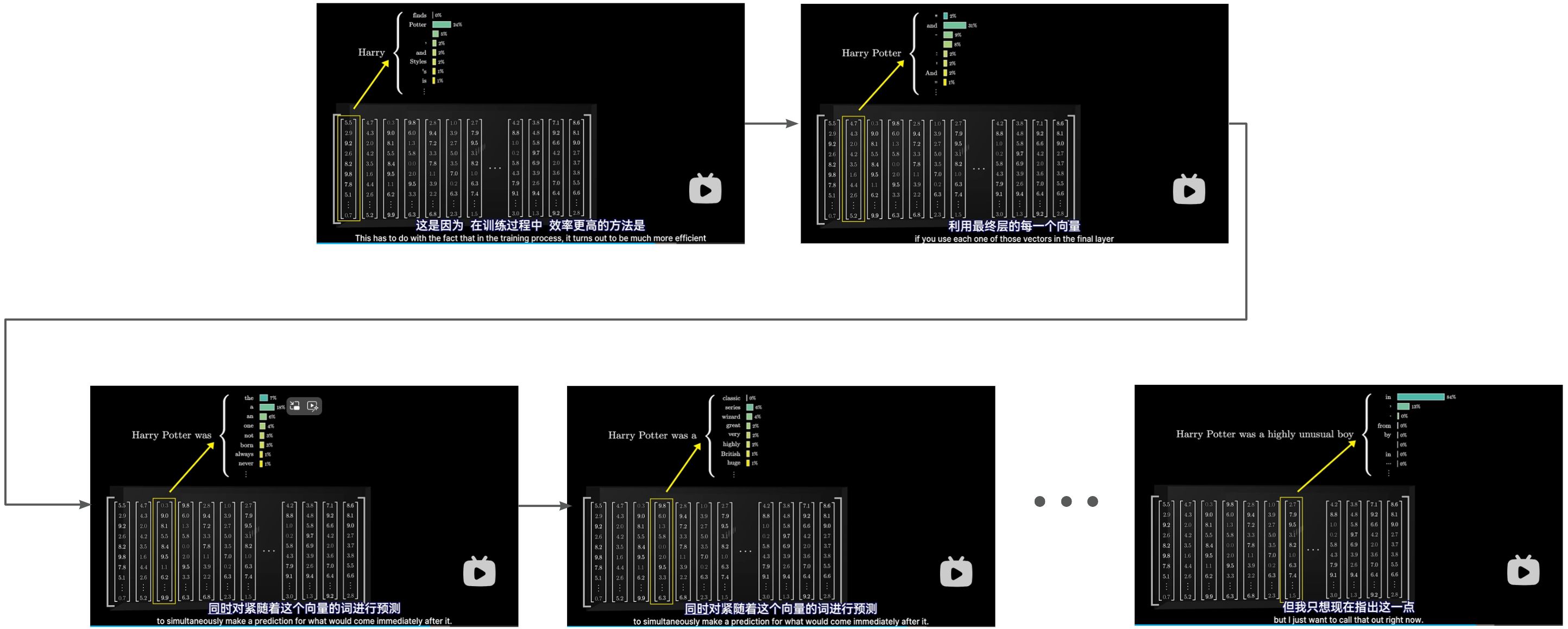
在训练过程中,效率最高的方法是利用最终层的每一个向量同时对紧随着这个向量的词进行预测(具体细节暂不列出)
Unembeding matrix
解嵌入矩阵Wu和其他权重矩阵一样,它的初始值随机,将在训练过程中学习,Wu的维度很好确定,一共50257行,12288列,他和Embedding matrix类似,只是行列对调,所以参数一共有大约6.17亿个参数:

注:softmax归一化之前的原始的未归一化的输出,一般会被成为logits
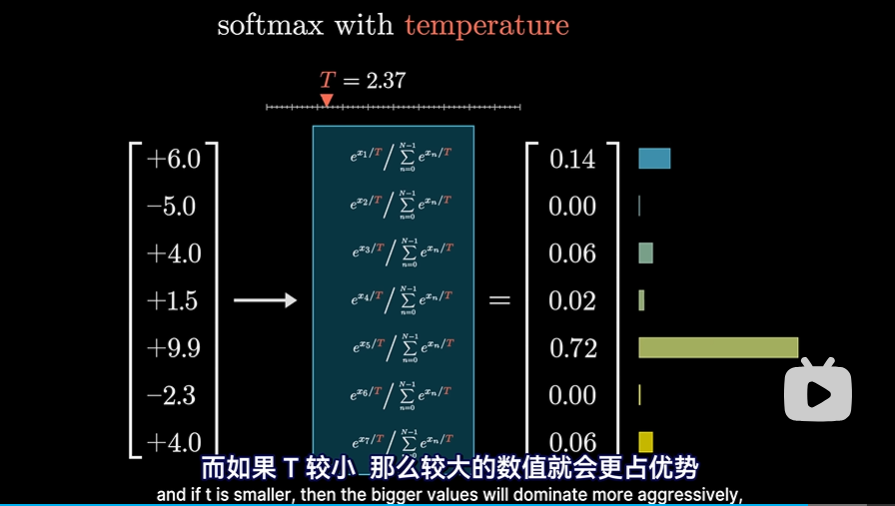
Softmax函数小改动
在某些情况下,例如chatGPT使用该分布生成下一词时,可以给这个函数加一些趣味性。给指数加个分母常量T,可以称之为“温度”:

- T越大,会给低值赋予更多的权重,使得分布更均匀一些。这样可能会使得GPT生成的故事更新颖一些,不过有可能最后演变为无稽之谈
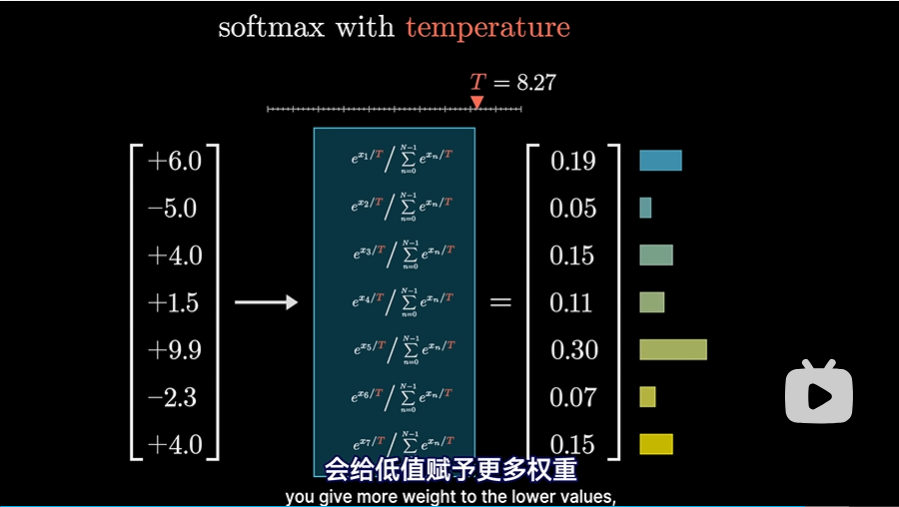
- T越小,较大的数值会更有优势。这会使GPT生成的故事更老套保守一些,但更不容易出现无稽之谈。
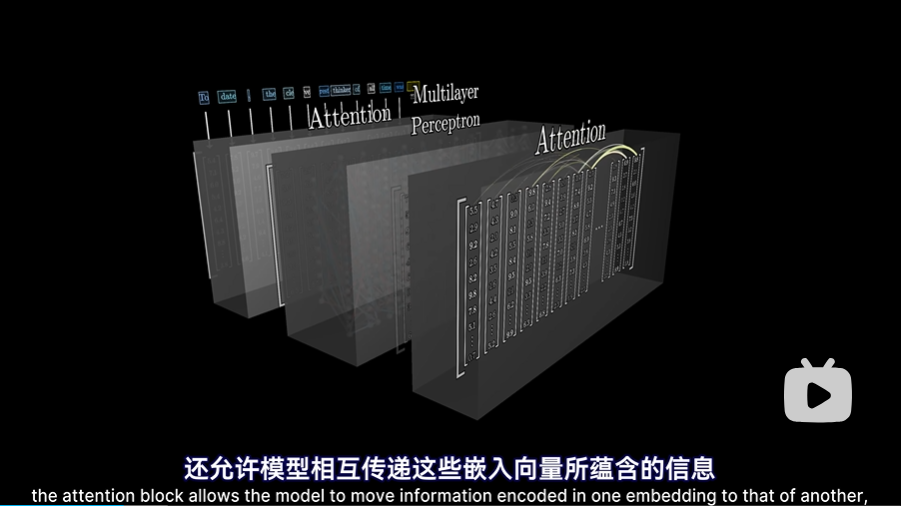
注意力机制
在所有可能的嵌入向量构成的高维空间中,方向可能对应语义。以一个例子来说明注意力机制要实现的目标(这里仅仅是帮助形象的理解,实际机制是很难解释的):
- 考虑词“tower”的嵌入向量,也许是高维空间中某个很泛型,不具体的方向,也可以认为在高维空间中表示泛型的一个向量,和“高大的物体”一类名词相关联。总而言之,是个很泛型不具体的词
- 如果这个词“tower”前面有一个词“Eiffel”,那应该有一个机制来更新这个“tower”向量,使更新后的向量更具体地指向 “埃菲尔铁塔”方向。
- 如果词前面还有一个词 “Miniature”,那么嵌入的向量应该会被进一步更新,使其不再和高大的事物相关联,可能和“埃菲尔铁塔模型”或者“埃菲尔铁塔挂件之类”有关联
- 图如下:

- 注意力模块不仅精细化了一个词的意义,还允许模型相互传递这些嵌入向量蕴含的信息,甚至可以传递的很远,即很远的上下文信息也可以相互传递
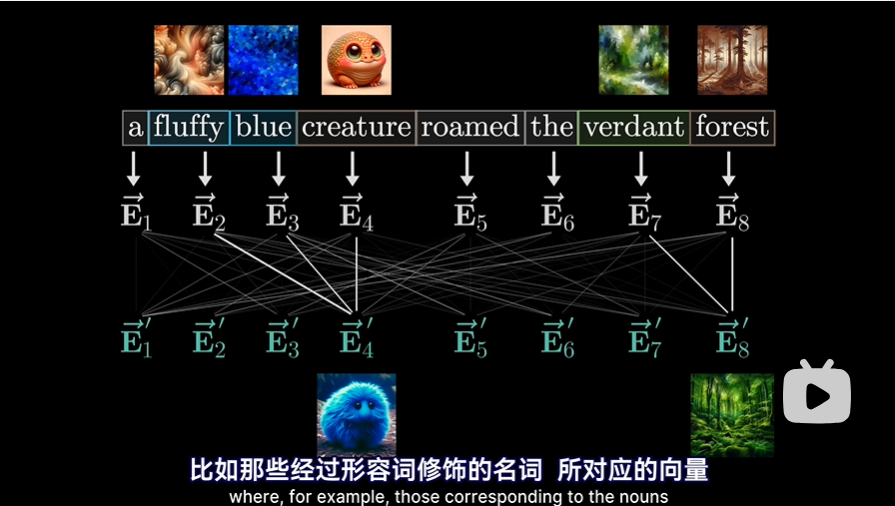
Single head of attention
以以下短语“a fluffy blue creature roamed the verdant forest”来说明和形象理解单头注意力机制,注意我们只关注“形容词调整对应名词的含义”这种类型的更新,以方便理解,实际注意力机制内部到底发生了什么是理解不了的,只是通过训练调整了大量的参数。需要再次注意两点:
- 每个词的初始嵌入是一个高维向量,编码了改词的含义,和上下文没有关联
- 向量还编码了词的位置信息(这里未详细说明,先跳过对这个的理解)
所以最终的目标是经过一些列的计算,产生一组新的,更为精准的嵌入向量(比如经过形容词修饰的名词所对应的向量),如下图:
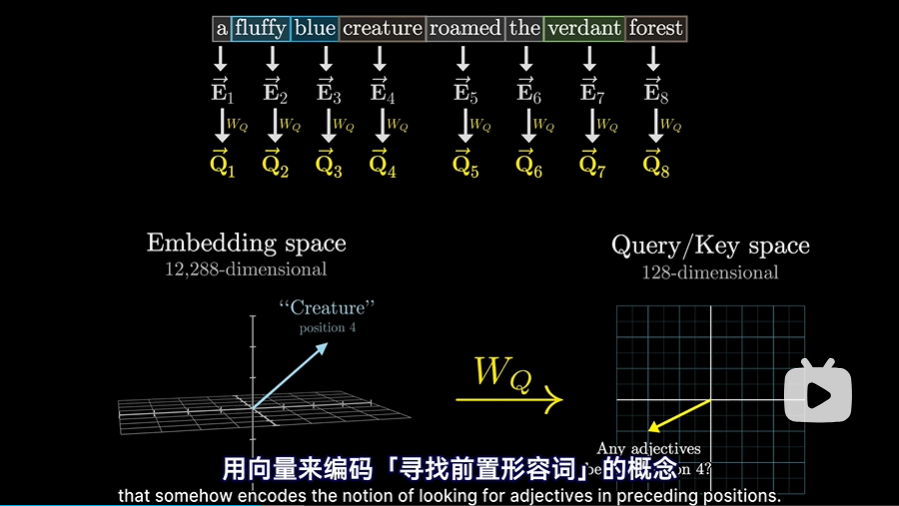
Q矩阵
- 每一个嵌入向量Ei,乘以一个WQ矩阵会得到一个Qi向量这个Qi向量仿佛在提出对应的问题(Query),比如我前面有形容词吗?
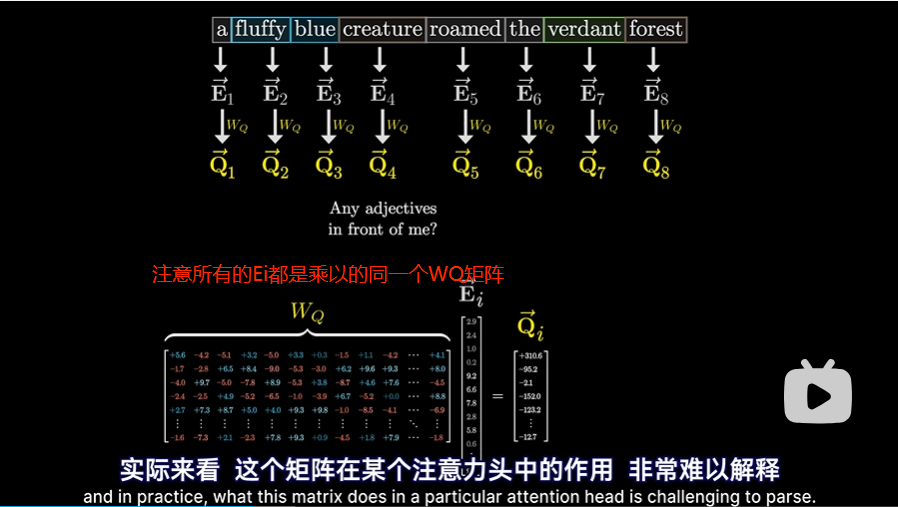
- WQ的行为128行,列和Ei的维度相同,即12288,这样每一个Qi就是一个128维度的列向量但需注意,这里WQ才是带参数的矩阵,称为查询矩阵,在训练过程中会不断调整。
- 为了方便理解,我们可以这么去认为:
- 这个查询矩阵WQ将“嵌入空间(12288维)”中的名词,映射到较小的“查询空间(128维)”中的某个方向,所有的Qi组成了Q矩阵
- 这个方向(或者说向量)编码了“寻找前置形容词”的概念
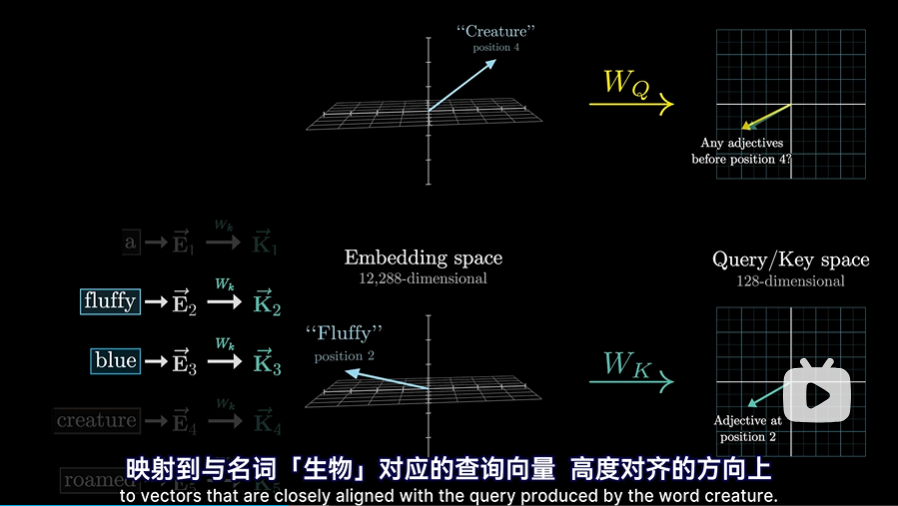
K矩阵
- Wk也会可每一个嵌入向量Ei相乘,产生第二个向量序列Ki,成为键(keys),可以把“键”视为想要回答“查询”,所有的Ki组成了K矩阵
- Wk也是一个可调参数的矩阵,称为键矩阵会在训练过程中不停变化,和查询矩阵一样,他也会将嵌入向量映射到相同的低纬度空间(也是128维度)

- 当“键”与“查询”的方向对齐时,就能认为他们相匹配。就本例而言,“键”矩阵会将形容词“fluffy毛茸茸的”和“blue蓝色”映射到与名词“creature生物”对应的查询向量Qi方向高度对齐的方向上。
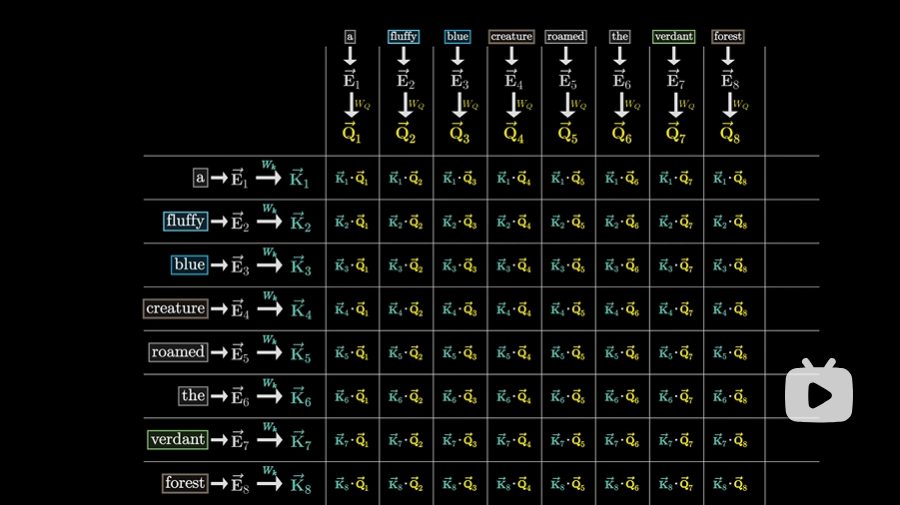
键-查询匹配程度
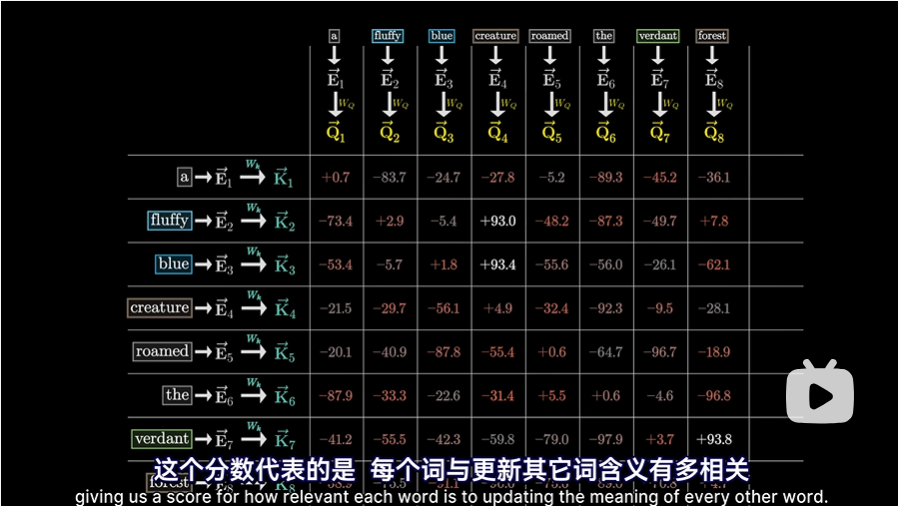
- 为了衡量每个“键”与每个“查询”匹配程度,计算所有可能的“键-查询”对之间的点积
- 形象地用圆点来表示,圆点越大,点积就越大,“键”与“查询”就越对齐
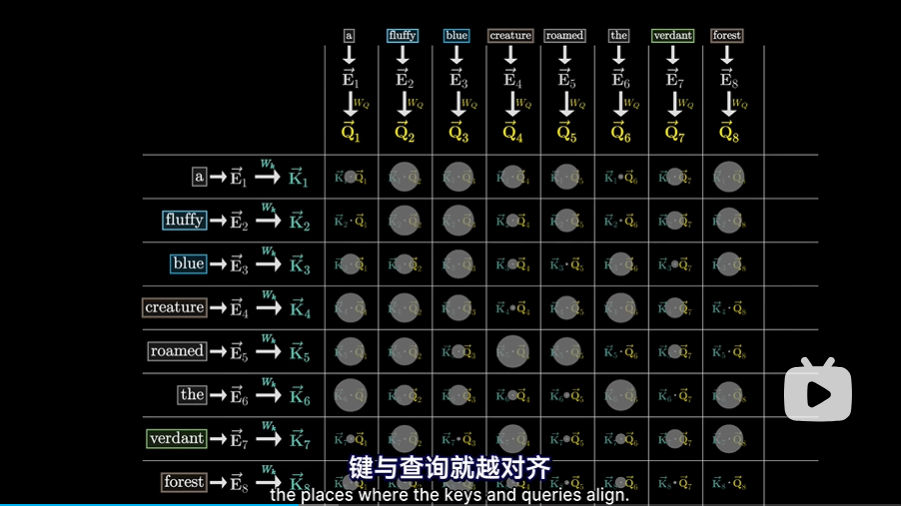
- 对于这个例子来说,由“fluffy毛茸茸”和“blue蓝色”生成的键确实与“creature生物”产生的查询高度对齐。用机器学习的方式描述就是“fluffy毛茸茸的”和“blue蓝色”的嵌入注意到了“creature生物”的嵌入

- 这样网格中的值可以是负无穷到正无穷的任何实数,这个值代表的是每个词与更新其他词含义有多相关,如果值小,意味着这个词对于更新其他词的含义相关性不大
- 对每一列使用Softmax进行归一化,注意这里是逐列计算Softmax
 这意味着此时就能将每一列看作权重,表示左侧的键与顶部的查询的相关程度
这意味着此时就能将每一列看作权重,表示左侧的键与顶部的查询的相关程度  这个网格称之为注意力模式(attention pattern)
这个网格称之为注意力模式(attention pattern)
- 论文中的表达方式,dk是为了数值稳定性,这个后面再理解:

训练过程
- 在训练过程中,效率比较高的方法是让模型同时预测每个初始token子序列之后所有可能的下一个token,这样一个样本就能提供多次训练机会
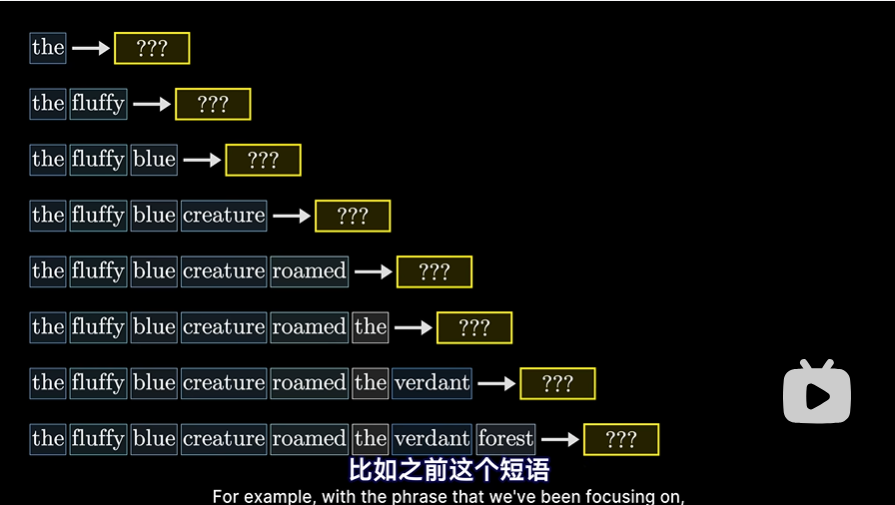 但这意味着,对于注意力模式而言,不能让后词影响前词,不然会泄露之后的答案,这样就没法进行上述所说的训练了。这意味着我们要使注意力模式的左下方,这些代表着后方token影响前方token的地方能被强制变为0
但这意味着,对于注意力模式而言,不能让后词影响前词,不然会泄露之后的答案,这样就没法进行上述所说的训练了。这意味着我们要使注意力模式的左下方,这些代表着后方token影响前方token的地方能被强制变为0 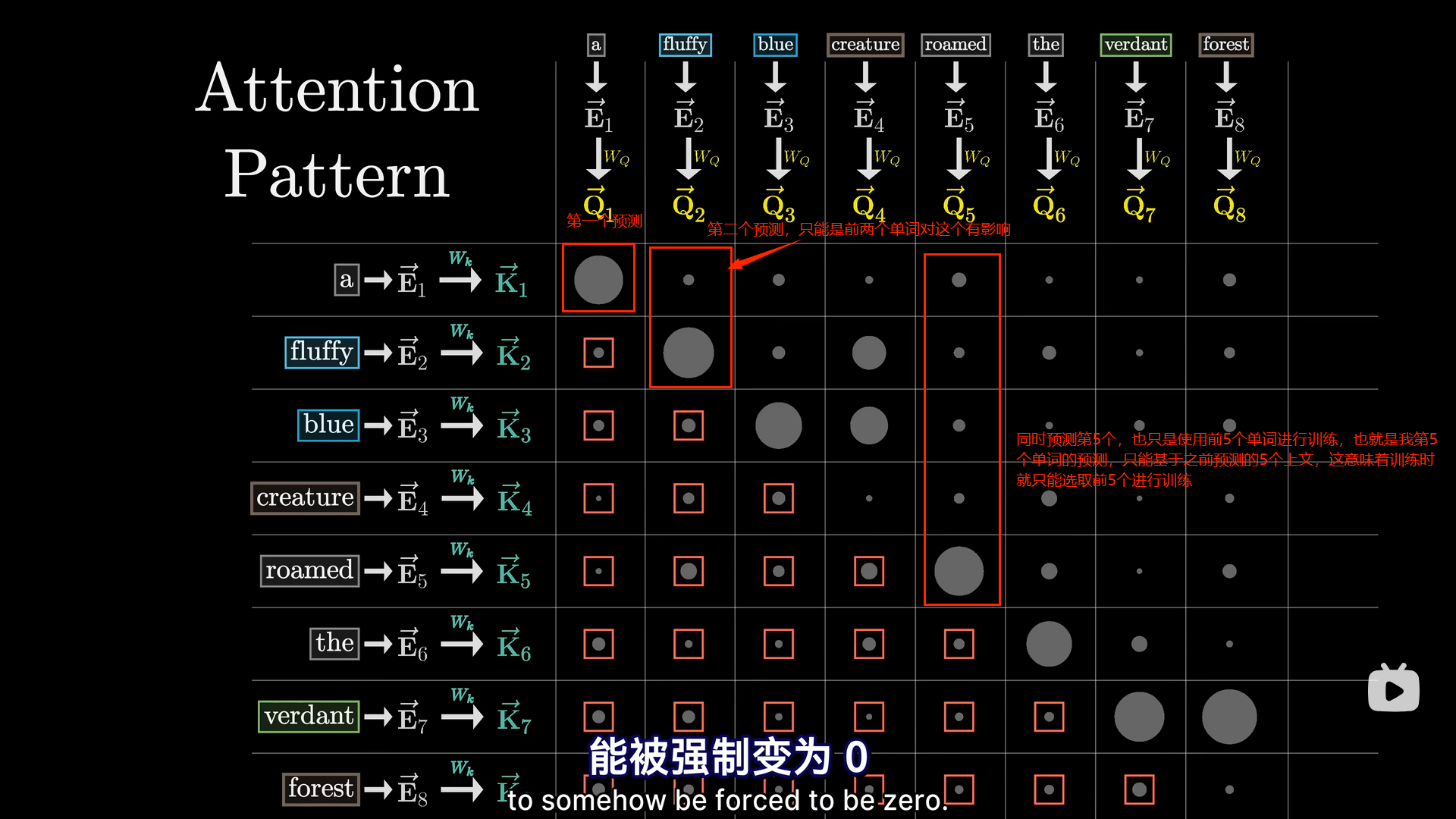 方法就是先将他们都设为负无穷,然后经过softmax后,这些地方就变为0了。这一过程称之为“掩码”,当然,有些注意力机制,并不使用掩码
方法就是先将他们都设为负无穷,然后经过softmax后,这些地方就变为0了。这一过程称之为“掩码”,当然,有些注意力机制,并不使用掩码 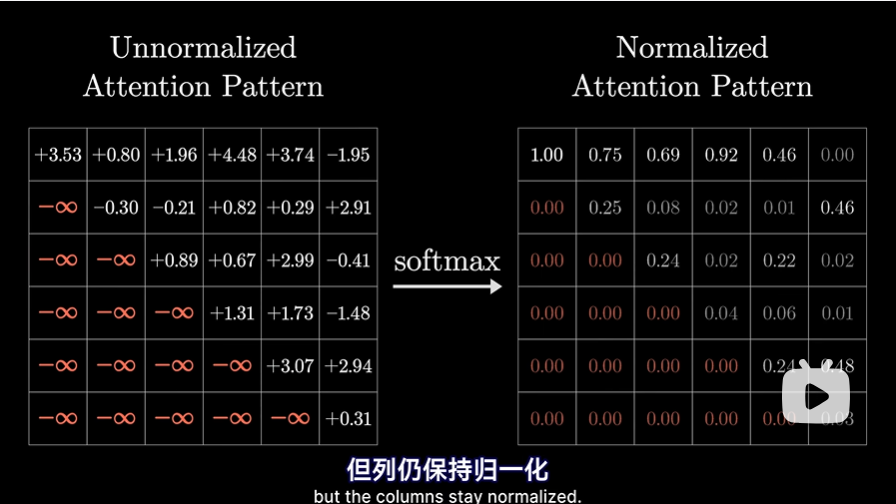
- 另一个注意的点是,注意力模式的大小,等于其上下文长度的平方。这也是为什么上下文长度会成为大语言模型的瓶颈。所以出现了许多的注意力机制变体,这里不介绍

V矩阵
- 算出该模式,就能让模型推断出每个词与其他哪些词有关。然后要做的就是去更新嵌入向量,把各词的信息传递给与之相关的其他词
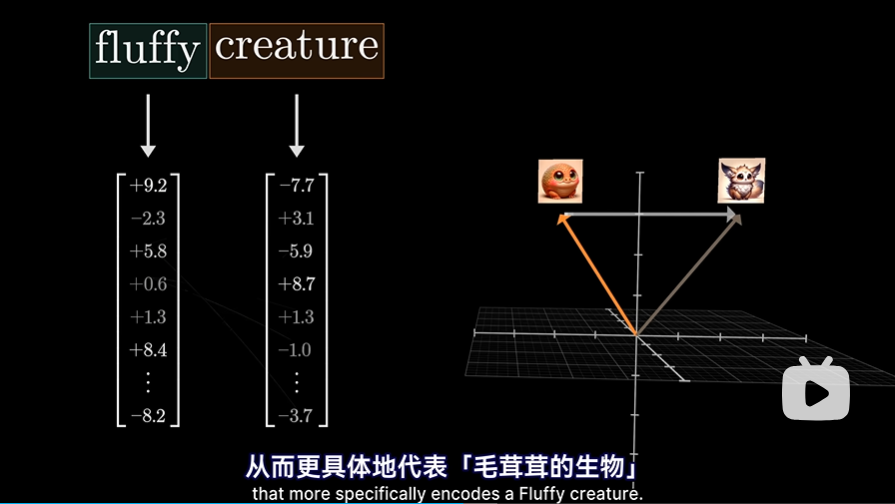
- 此时就要引入值权重矩阵Wv,用它乘以前面那个词的嵌入向量(如fluffy)得到值向量,这就是你要给后面的词嵌入(如creature)所加的向量。所以值向量与嵌入向量处于同一个高维空间。可以这样理解:如果这个词,需要调整目标词的含义,那么要反映这一点,得对目标词的嵌入,加上什么向量呢?
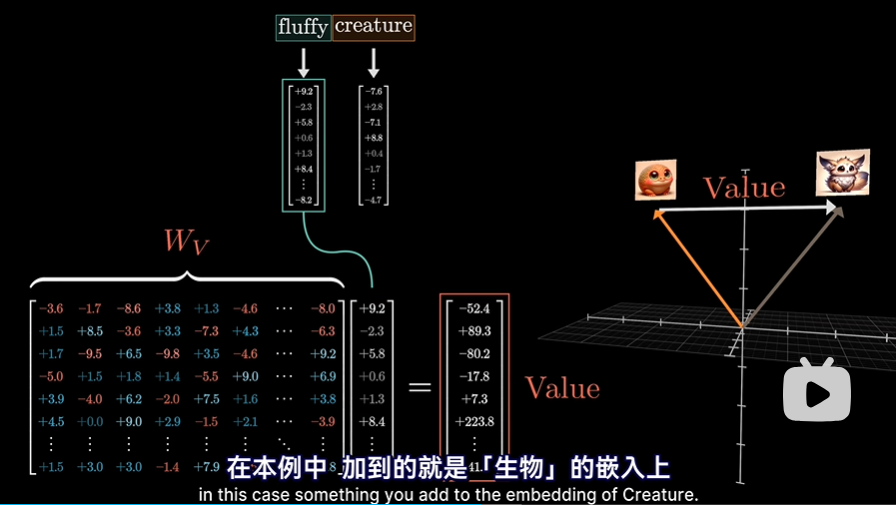
- 再次回到注意力模式网格,通过之前的Q K矩阵,我们已经计算出了各个单词之间的注意力模式,那么其实接下来需要的就是,利用Wv矩阵,计算出一系列值向量。这些值向量,可以想象成是与对应的键向量相关联。然后:
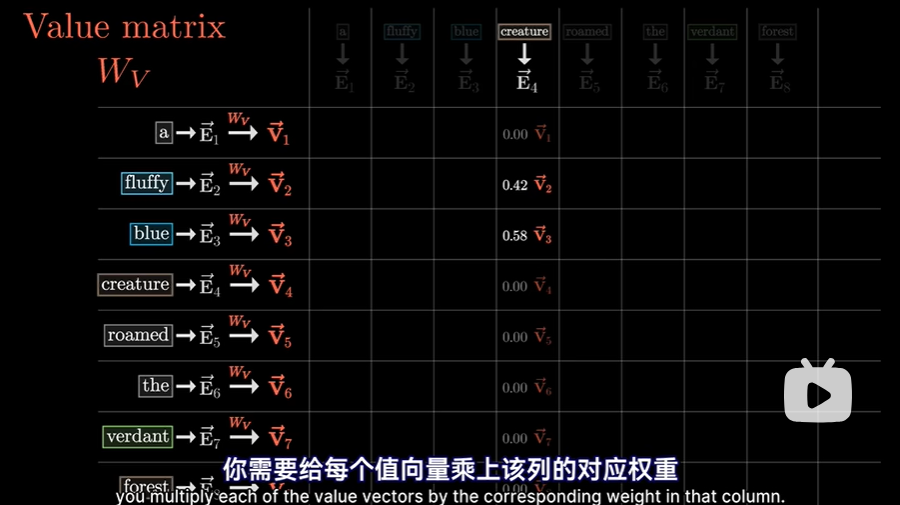
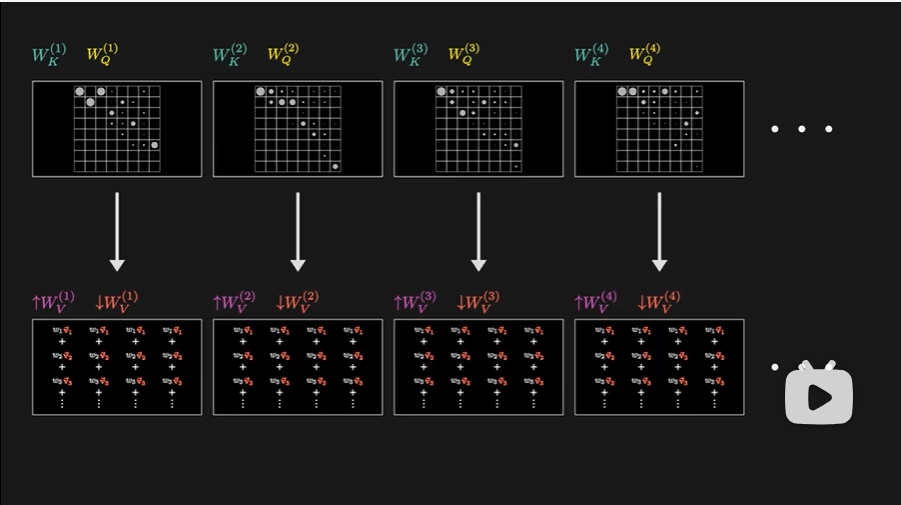
- 对每个值向量,乘上该列对应的权重,这里也好理解,因为权重越大意味着这两个词关联性越强。例如这里对于“creature生物”一词的嵌入,要加上“fluffy毛茸茸的”和“blue蓝色的”的值向量的大部分贡献。
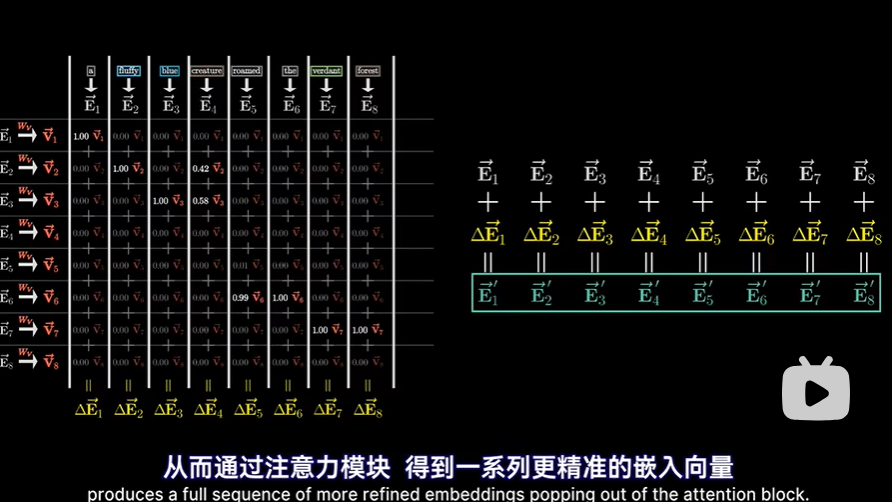
- 然后为了更新该列对应的嵌入向量,也就是一上来没有上下文含义的“creature生物”的词嵌入,将该列中所有带权值的值向量加和(加权和)得到想要引入的变化量δE,然后把这个δE加入到原始的嵌入向量上,预期得到一个更精准的向量,编码了更丰富的上下文信息

- 当然不只是一列,而是对每一列都进行上述的操作,从而通过注意力模块,得到一系列更精准的嵌入向量
- 对每个值向量,乘上该列对应的权重,这里也好理解,因为权重越大意味着这两个词关联性越强。例如这里对于“creature生物”一词的嵌入,要加上“fluffy毛茸茸的”和“blue蓝色的”的值向量的大部分贡献。
小结
上述整个过程就是单头注意力的过程,这个过程由三种充满了可调参数的矩阵实现,the key, the query, the value。

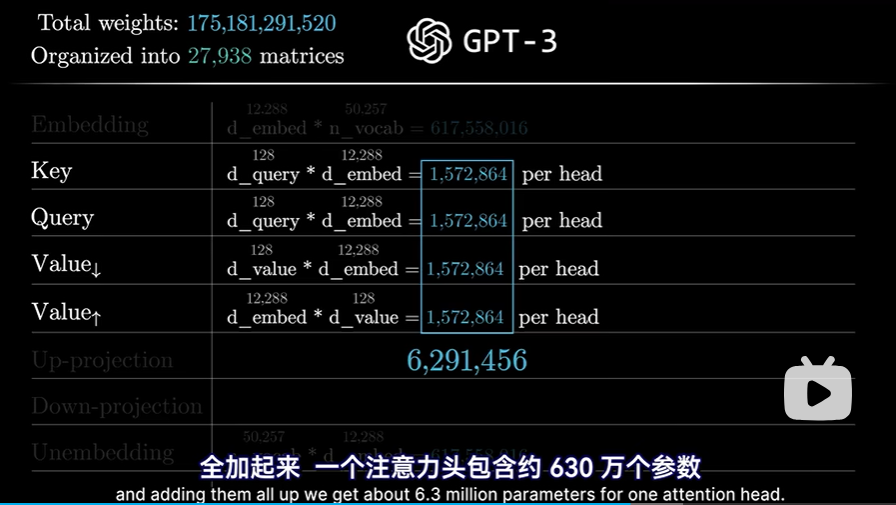
接下来稍稍计算一下整体参数量
- Key和Query矩阵均是128行,12288列,大约每一个150万个参数

- 对于值矩阵,因为其输出和输出都在嵌入空间,所以应当是一个12288的方阵
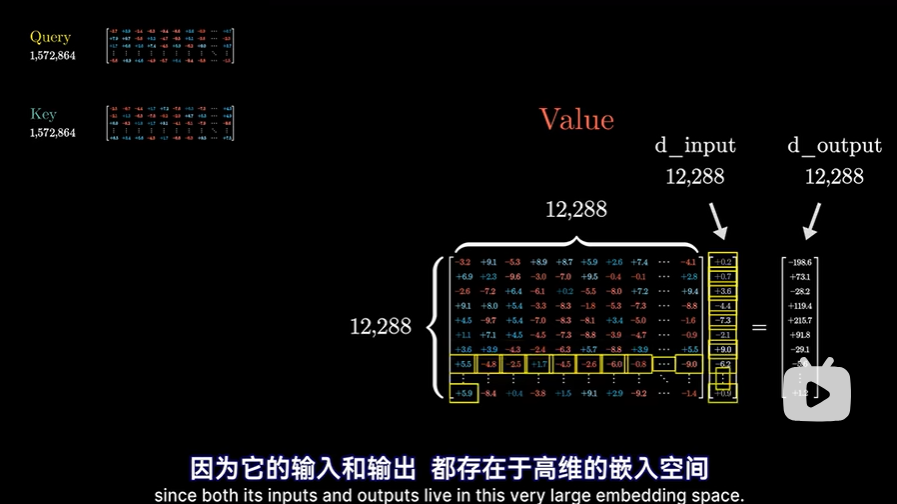 如果真这样做,这意味着要增加约1.5亿个参数:
如果真这样做,这意味着要增加约1.5亿个参数: 但实际上更高效的做法是让值矩阵所需的参数量=键矩阵参数量+查询矩阵参数量,这对并行运行多个注意力头来说,至关重要。方法就是将值矩阵分解为两个小矩阵的乘积。但还是要把这两个整体看成一个映射矩阵,属于嵌入空间到嵌入空间的映射
但实际上更高效的做法是让值矩阵所需的参数量=键矩阵参数量+查询矩阵参数量,这对并行运行多个注意力头来说,至关重要。方法就是将值矩阵分解为两个小矩阵的乘积。但还是要把这两个整体看成一个映射矩阵,属于嵌入空间到嵌入空间的映射 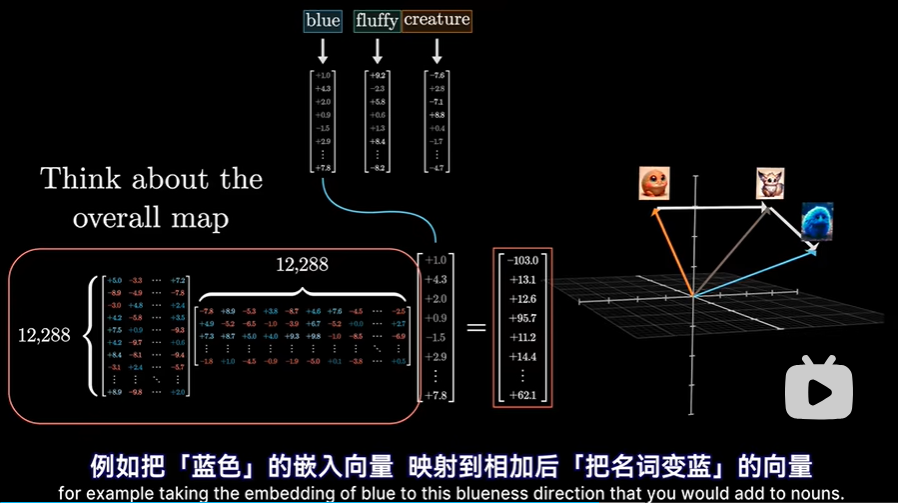 只是实践上分成两步:
只是实践上分成两步:- 右边第一个矩阵,可以看作是将较大的嵌入向量,降维到较小空间,非官方命名,临时叫作value down matrix
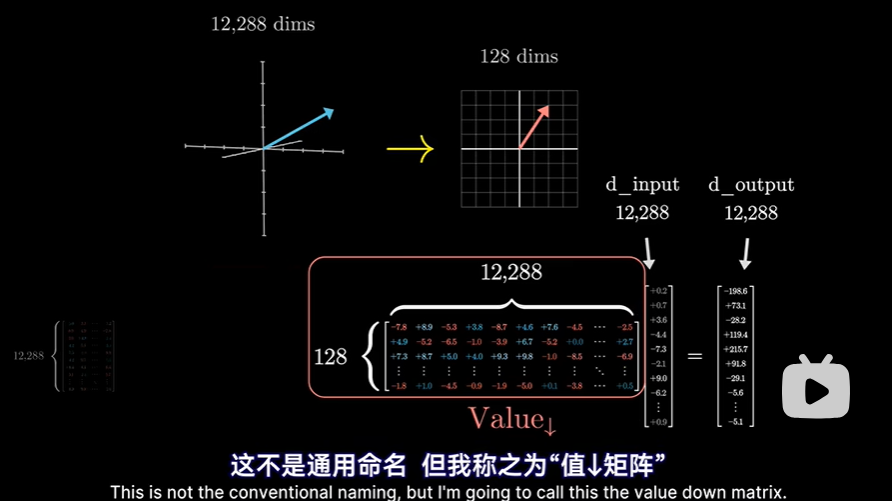
- 左侧的第二个矩阵,则是从小空间映射回嵌入空间,非官方命名,叫作 value up matrix
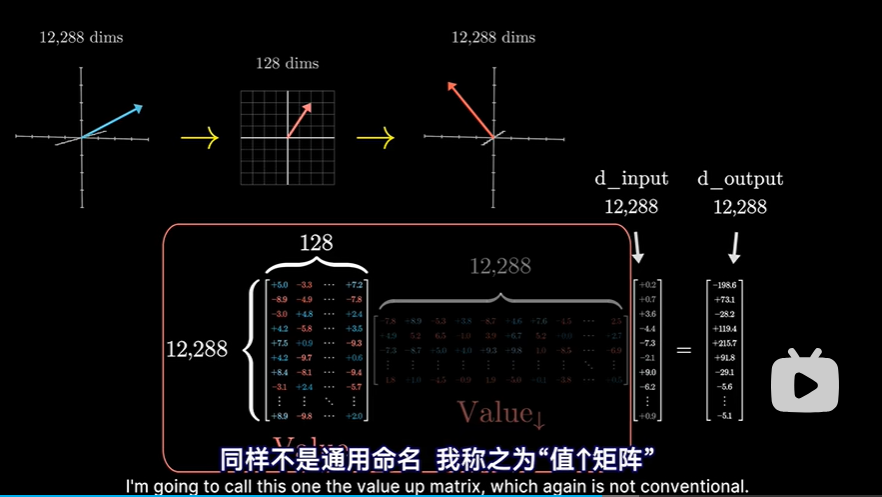
- 右边第一个矩阵,可以看作是将较大的嵌入向量,降维到较小空间,非官方命名,临时叫作value down matrix
- 把他们加起来,一个注意力头(自注意力头)包含约630万个参数
Multi-headed attention
- Transformer内完整的注意力模块(对于GPT,这个注意力模块也有多个!!!),由多头注意力组成,大量并行的执行类似于单头注意力的操作。我们可以认为每一个单头注意力有不同的注意力模式。

- 96个注意力头,产生96个不同的注意力模式,每个注意力头都有独特的值矩阵,用来产生96个“值向量序列”
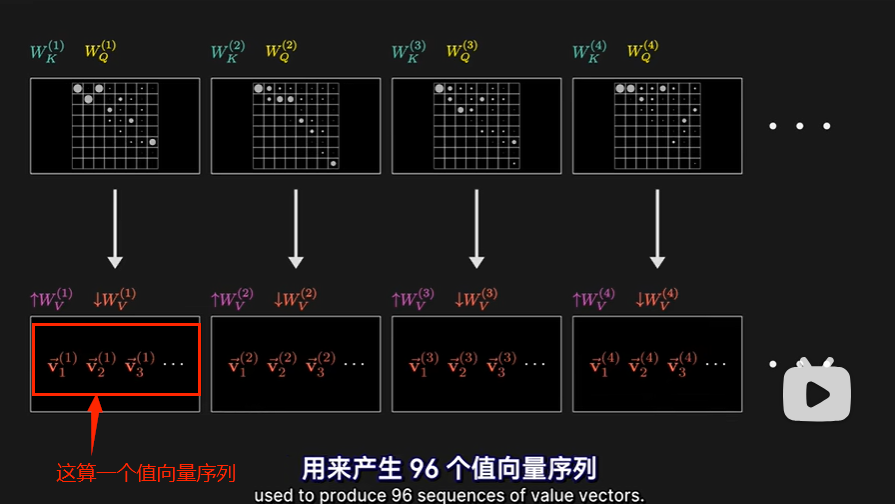
- 全部都将以对应注意力模式作为权重,分别进行加权求和
- 这意味着,对于上下文中的每个位置,也就是每个token,每个注意力头都会给出一个要加入到该位置嵌入向量的变化量,然后要做的就是把各个注意力头给出的变化量加起来,然后给该位置的初始嵌入加上这个加和
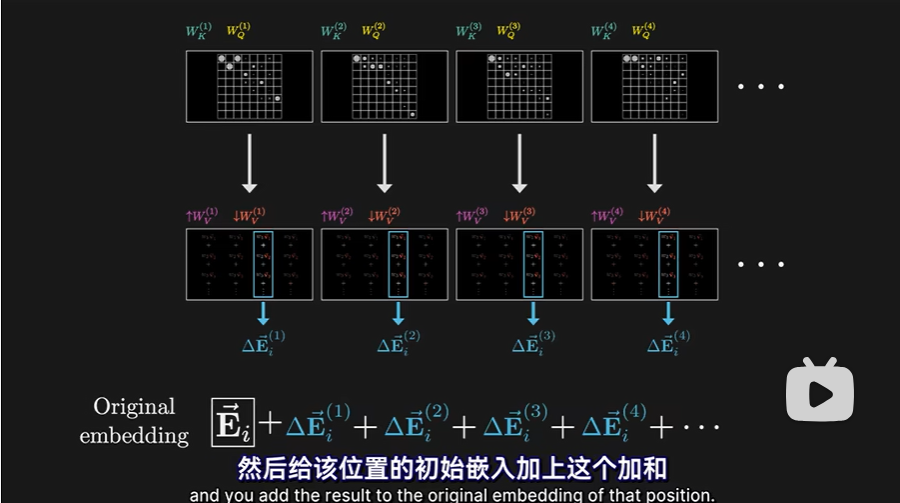 这个总和,就是多头注意力模块输出的一列。也即通过这个模块,能得到一个更精准的嵌入
这个总和,就是多头注意力模块输出的一列。也即通过这个模块,能得到一个更精准的嵌入 
- 全部都将以对应注意力模式作为权重,分别进行加权求和
- 整体可以这样去理解:通过并行多头运算,模型能学习到根据上下文来改变语义的多种方式

- 参数统计:
- 每个多头注意力模块,最终会有大约6亿个参数(注意这里是每个多头注意力模块)

- 每个多头注意力模块,最终会有大约6亿个参数(注意这里是每个多头注意力模块)
GPT组成
- 对于GPT来说,有许多个Attention模块,每个Attention模块之间通过神经网络(多层感知层)连接

- GPT-3包含了96个不同的层,所以 键、查询、值的参数总和,还得再乘以96,使得所有注意力头参数总和接近580亿个

- 580亿参数量很多,但也只占了整个网络参数量1750亿的大约三分之一,所以其实大量参数都来自于Attention模块之间的多层感知模块

- 多层感知模块即神经网络的介绍此处不涉及
参考
- 【【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章】 https://www.bilibili.com/video/BV13z421U7cs/?share_source=copy_web&vd_source=2d06b9a293d399ed58c19e183f9d84da
- 【【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】】 https://www.bilibili.com/video/BV1TZ421j7Ke/?share_source=copy_web&vd_source=2d06b9a293d399ed58c19e183f9d84da

